Picture yourself in a bustling office, your inbox flooded with emails and PDFs. Every day, your team spends hours manually extracting data from these digital documents, prone to errors and inefficiencies. Now, imagine a world where this tedious task is automated, freeing up your time for more strategic work. Welcome to the future with DICE – where AI and machine learning revolutionize document processing.
Our commitment to innovation ensures we remain at the forefront of technology, continuously evolving to meet new challenges.
Our document processing solutions drive efficiency, accuracy, and informed decision-making with advanced features like document identification, data extraction, and reporting. Our intuitive tools adapt to your unique needs, streamlining processes and reducing costs.
Effortlessly connect DICE with your existing business systems and workflows, ensuring smooth data transfer. We help you meet your unique business requirements, ensuring optimal performance and user satisfaction.
Experience the magic with us.
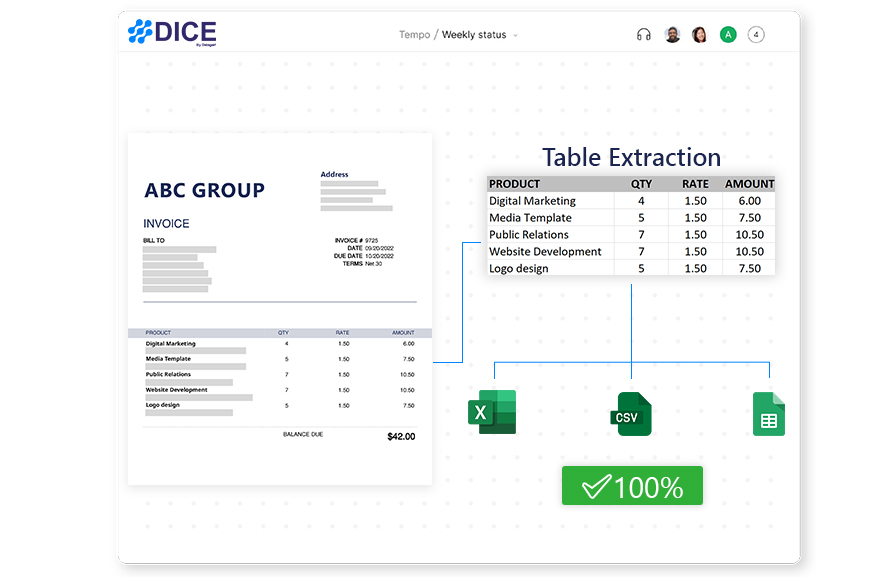
We utilize cutting-edge AI to identify table regions accurately. DICE, our proprietary OCR engine ensures high accuracy across diverse document types.
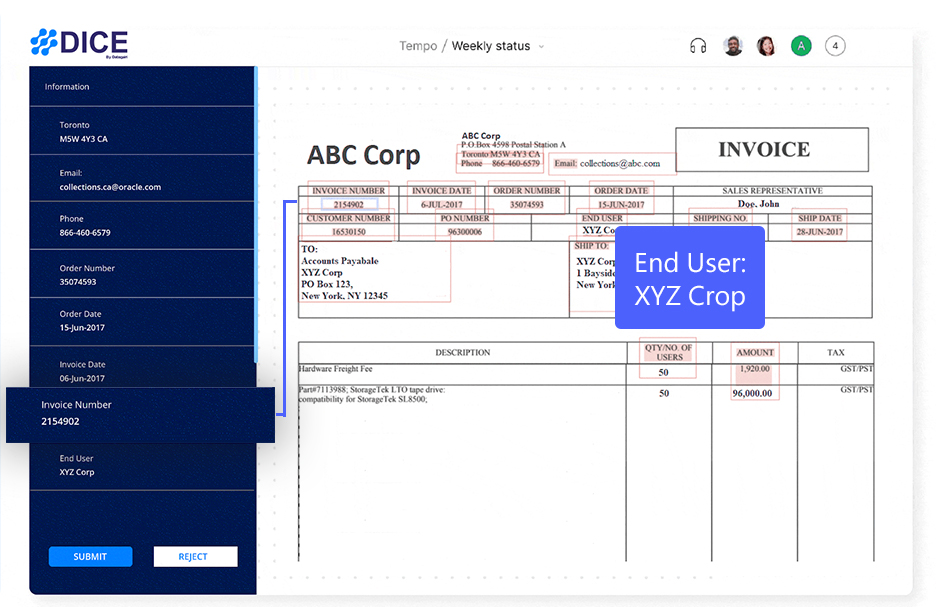
Our system is designed to handle varied table layouts and formats, adapting to the unique structures of each document to extract data accurately.
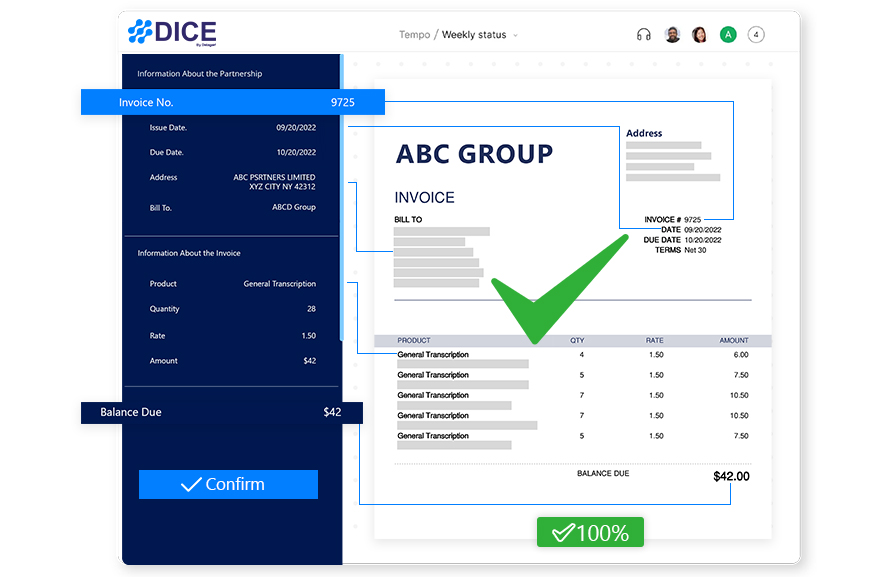
Ensuring data accuracy is paramount. We employ intelligent validation and correction, applying data validation rules and removing unnecessary characters to maintain high-quality outputs. We add a layer of human-in-the-loop validation to facilitate accurate output and adaptive learning for the OCR engines.
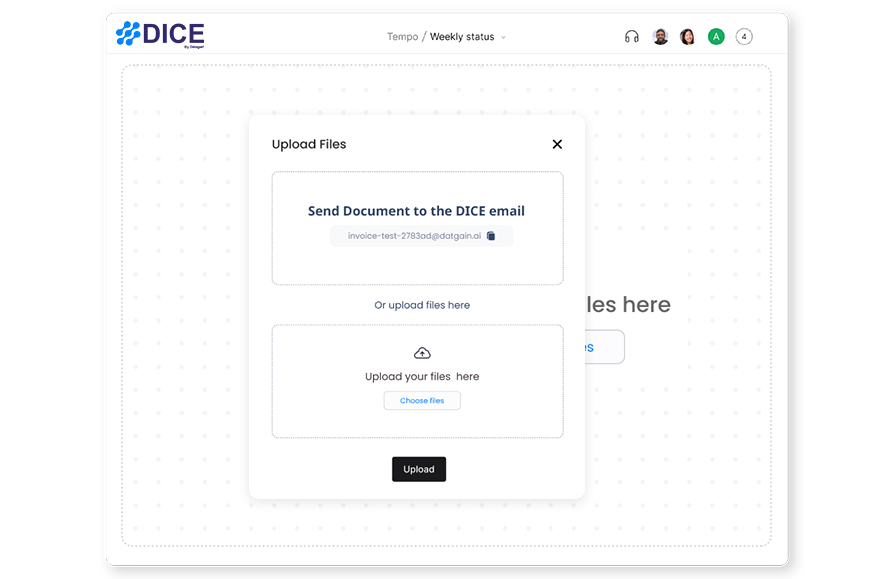
Upload your PDFs and witness the extraction process in action. Our intuitive interface makes it easy to see how our technology can transform your document processing workflows.
We ensure you can navigate the extraction process effortlessly, making data validation and correction straightforward.
Try our services, schedule a demo, or contact us for more information. Join the revolution and embrace the future of document processing with DICE.
DICE’s advanced technology streamlines table extraction from PDFs and images, addressing modern data challenges with precision and efficiency. Our comprehensive approach, from document upload to data validation and reporting, ensures a seamless, user-friendly experience, empowering businesses across various industries to unlock new efficiencies and enhance their document processing workflows.
Transform your workflows, enhance accuracy, and unlock new efficiencies today.Stay ahead of the curve with insights into the next big things in document processing and AI with us.